Here is one of the most misunderstood aspects of AWS Lambda
|
One of the most misunderstood aspects of Lambda is how throttling applies to async invocations. Or rather, how it doesn't! Every Lambda invocation has to go through its Invoke API [1], whether you're invoking the function directly or through an event source such as API Gateway or SNS. With the Invoke API, you can choose invocationType as either "RequestResponse" (i.e. synchronous) or "Event" (i.e. asynchronous). Synchronous invocationsWith synchronous invocations, throttling limits are checked to make sure you stay within:
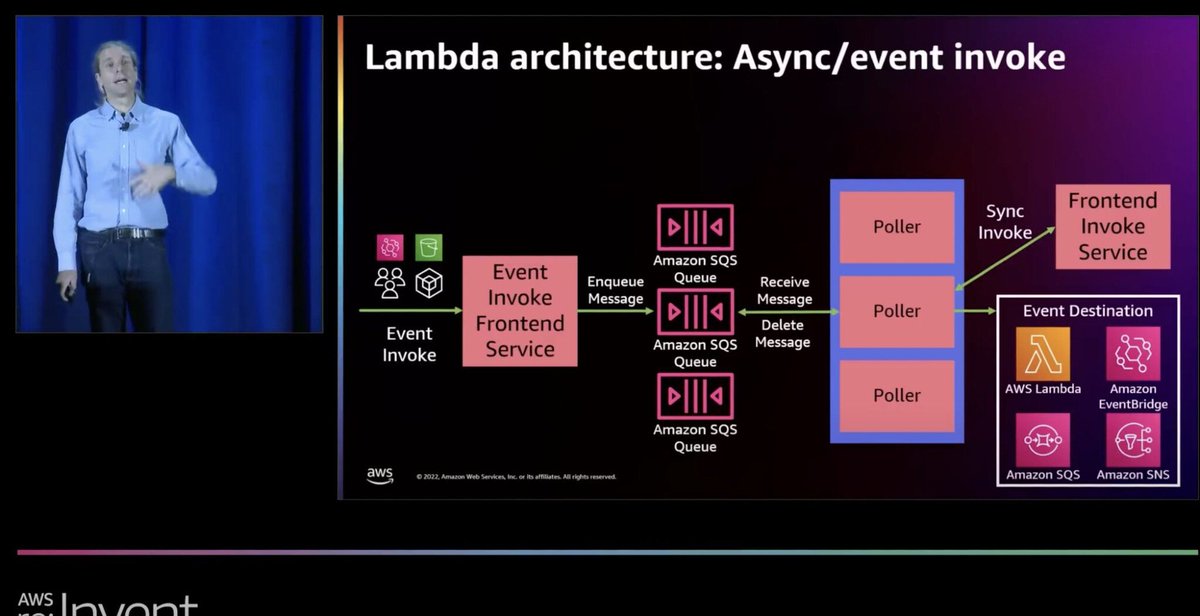
However, this is not true for async invocations. Async invocationsWith asynchronous invocations, the Event Invoke Frontend service (see diagram below) accepts the request and passes it onto an internal queue. It does not check the concurrency limits and will succeed even if the function does not have the concurrency to process the request. But that's OK because it does not have to process the request right away, given the asynchronous nature of the invocation.
Instead, concurrency limits are checked when the internal poller attempts to invoke the function synchronously. This means that you will never experience throttling when you invoke a function asynchronously. Even if you set the reserved concurrency to 0 - which will stop the function from running - the "Event" Invoke call will still succeed. But what happens when the internal poller invokes the function synchronously and the function is throttled? In that case, the invocation request is returned to the internal queue and is retried for up to 6 hours. This is described in the official documentation here [3]. Async invocations vs. Async event sourcesAnother important detail to consider is that async event sources such as SNS and EventBridge also invoke Lambda asynchronously. This means, even though they each offer a longer retry period:
But, because async invocations never fail due to throttling, so they count as successful deliveries for SNS and EventBridge. Lambda's Event Invoke Frontend service accepts the request, and any throttling errors will be retried for up to 6 hours ONLY. I asked about this on Twitter, and two of the principal engineers on the Lambda team confirmed my hypothesis above. See their responses here and here. So what?Why do these details matter? Quite a few of you have told me that you prefer SNS -> Lambda over a direct async Lambda invocation because it protects against throttling errors. Good news, given the above, you don't need the SNS topic! (unless you need it for fan-out) This is a good thing because:
You are welcome :-) This follows one of my most important architectural principles and I think you should follow it too. Aren't Lambda-to-Lambda calls an anti-pattern?Yes, synchronous Lambda-to-Lambda calls are an anti-pattern. However, there are valid use cases for asynchronous Lambda-to-Lambda calls. For example, when you offload secondary responsibilities (e.g. analytics tracking) from a user-facing API function to a second function and invoke it asynchronously. This is so that:
These benefits justify the extra cost of invoking a second function instead of doing everything in the API function. Links[1] Lambda's Invoke API [2] AWS re:Invent 2022 - A closer look at AWS Lambda (SVS404-R) [3] How Lambda handles errors and retries with asynchronous invocation |
Master Serverless
Join 17K readers and level up you AWS game with just 5 mins a week.
Modern applications rarely do just one thing at a time. An API request creates an order, and then another service needs to reserve stock, another to charge the customer, another to send an email, and so on. In a serverless or event-driven architecture, follow-up actions are usually triggered by messages (either events or commands). That gives us loose coupling, better scalability, and independent services. But it also introduces a reliability problem. “What happens when the database update...
If you use Claude Code a lot, you’ve probably run into usage limits, sometimes even in short coding sessions. But cost isn’t the only problem. In long-running sessions, the context window eventually fills up, and that can cause the agent to forget earlier decisions, lose important details, or come back from compaction with gaps in its working memory. Here are three tools worth checking out if you want to reduce token usage and make longer coding sessions possible. 1. CavemanThis is a Claude...
AI agents can now scan an entire open-source codebase for exploitable vulnerabilities in hours. Frontier models carry the complete library of known bug classes in their weights. So you can simply point an AI agent at a codebase and tell it to find zero-days. This isn't theoretical. Willy Tarreau, the HAProxy lead developer, reports that security bug reports have jumped from 2–3 per week to 5–10 per day. Greg Kroah-Hartman, the Linux kernel maintainer, described what happened: "Months ago, we...